








Tremendous Useful Tips To enhance Deepseek
페이지 정보

본문
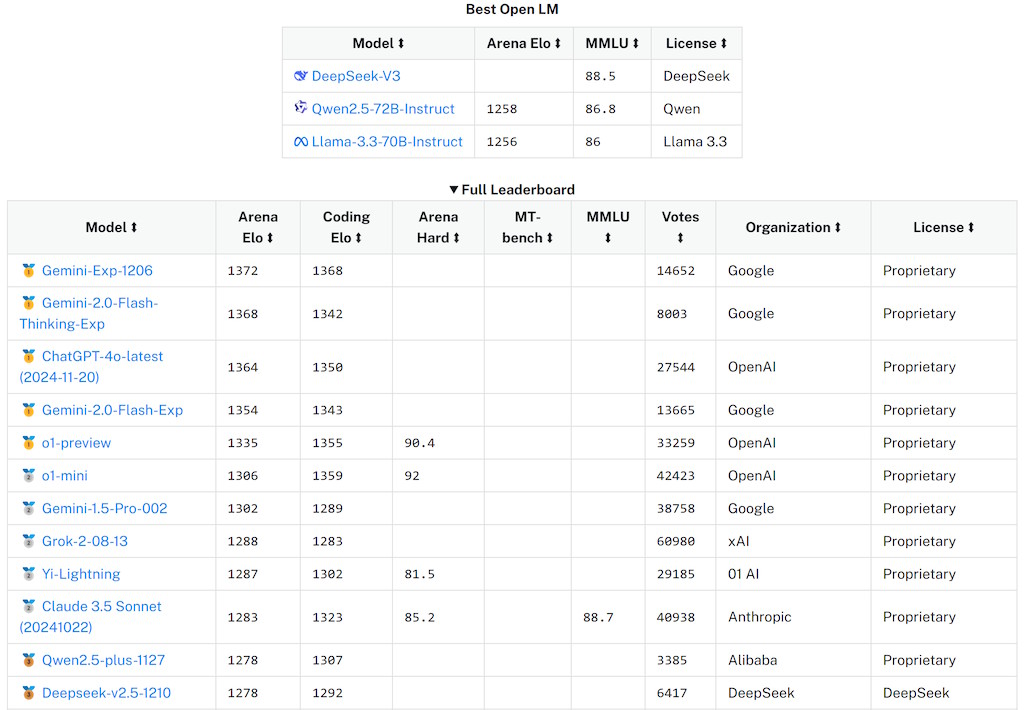 The company additionally claims it solely spent $5.5 million to practice DeepSeek V3, a fraction of the event price of fashions like OpenAI’s GPT-4. Not solely that, StarCoder has outperformed open code LLMs like the one powering earlier versions of GitHub Copilot. Assuming you may have a chat model arrange already (e.g. Codestral, Llama 3), you possibly can keep this complete expertise local by offering a hyperlink to the Ollama README on GitHub and asking inquiries to learn more with it as context. "External computational assets unavailable, local mode only", said his telephone. Crafter: A Minecraft-impressed grid environment where the participant has to discover, collect sources and craft gadgets to make sure their survival. It is a guest publish from Ty Dunn, Co-founder of Continue, that covers the right way to arrange, discover, and work out one of the best ways to make use of Continue and Ollama collectively. Figure 2 illustrates the fundamental architecture of DeepSeek-V3, and we'll briefly assessment the small print of MLA and DeepSeekMoE on this section. SGLang at present supports MLA optimizations, FP8 (W8A8), FP8 KV Cache, and Torch Compile, delivering state-of-the-artwork latency and throughput efficiency among open-source frameworks. In addition to the MLA and DeepSeekMoE architectures, it also pioneers an auxiliary-loss-free deepseek technique for load balancing and units a multi-token prediction training goal for stronger efficiency.
The company additionally claims it solely spent $5.5 million to practice DeepSeek V3, a fraction of the event price of fashions like OpenAI’s GPT-4. Not solely that, StarCoder has outperformed open code LLMs like the one powering earlier versions of GitHub Copilot. Assuming you may have a chat model arrange already (e.g. Codestral, Llama 3), you possibly can keep this complete expertise local by offering a hyperlink to the Ollama README on GitHub and asking inquiries to learn more with it as context. "External computational assets unavailable, local mode only", said his telephone. Crafter: A Minecraft-impressed grid environment where the participant has to discover, collect sources and craft gadgets to make sure their survival. It is a guest publish from Ty Dunn, Co-founder of Continue, that covers the right way to arrange, discover, and work out one of the best ways to make use of Continue and Ollama collectively. Figure 2 illustrates the fundamental architecture of DeepSeek-V3, and we'll briefly assessment the small print of MLA and DeepSeekMoE on this section. SGLang at present supports MLA optimizations, FP8 (W8A8), FP8 KV Cache, and Torch Compile, delivering state-of-the-artwork latency and throughput efficiency among open-source frameworks. In addition to the MLA and DeepSeekMoE architectures, it also pioneers an auxiliary-loss-free deepseek technique for load balancing and units a multi-token prediction training goal for stronger efficiency.
 It stands out with its means to not solely generate code but in addition optimize it for efficiency and readability. Period. Deepseek just isn't the issue you should be watching out for imo. In line with DeepSeek’s inside benchmark testing, DeepSeek V3 outperforms both downloadable, "openly" available fashions and "closed" AI fashions that can solely be accessed by way of an API. Bash, and extra. It can be used for code completion and debugging. 2024-04-30 Introduction In my earlier submit, I tested a coding LLM on its skill to write down React code. I’m probably not clued into this a part of the LLM world, but it’s good to see Apple is putting in the work and the community are doing the work to get these operating great on Macs. From 1 and 2, it is best to now have a hosted LLM mannequin operating. ???? Internet Search is now dwell on the web! DeepSeek, being a Chinese company, is subject to benchmarking by China’s web regulator to make sure its models’ responses "embody core socialist values." Many Chinese AI techniques decline to answer matters which may increase the ire of regulators, like hypothesis concerning the Xi Jinping regime.
It stands out with its means to not solely generate code but in addition optimize it for efficiency and readability. Period. Deepseek just isn't the issue you should be watching out for imo. In line with DeepSeek’s inside benchmark testing, DeepSeek V3 outperforms both downloadable, "openly" available fashions and "closed" AI fashions that can solely be accessed by way of an API. Bash, and extra. It can be used for code completion and debugging. 2024-04-30 Introduction In my earlier submit, I tested a coding LLM on its skill to write down React code. I’m probably not clued into this a part of the LLM world, but it’s good to see Apple is putting in the work and the community are doing the work to get these operating great on Macs. From 1 and 2, it is best to now have a hosted LLM mannequin operating. ???? Internet Search is now dwell on the web! DeepSeek, being a Chinese company, is subject to benchmarking by China’s web regulator to make sure its models’ responses "embody core socialist values." Many Chinese AI techniques decline to answer matters which may increase the ire of regulators, like hypothesis concerning the Xi Jinping regime.
Chatbot Navigate China’s Censors? Vivian Wang, reporting from behind the great Firewall, had an intriguing dialog with DeepSeek’s chatbot. As an open-source LLM, DeepSeek’s model may be utilized by any developer without spending a dime. DeepSeek V3 can handle a spread of textual content-based mostly workloads and tasks, like coding, translating, and writing essays and emails from a descriptive prompt. Like different AI startups, together with Anthropic and Perplexity, DeepSeek released various aggressive AI fashions over the past yr which have captured some business attention. For example, you need to use accepted autocomplete ideas from your team to superb-tune a model like StarCoder 2 to give you better ideas. Assuming you might have a chat mannequin arrange already (e.g. Codestral, Llama 3), you possibly can keep this entire experience native thanks to embeddings with Ollama and LanceDB. LM Studio, a straightforward-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. At inference time, this incurs greater latency and smaller throughput as a result of reduced cache availability. Despite the effectivity advantage of the FP8 format, certain operators nonetheless require a better precision attributable to their sensitivity to low-precision computations.
These activations are additionally used within the backward pass of the attention operator, which makes it sensitive to precision. We validate the proposed FP8 combined precision framework on two model scales much like DeepSeek-V2-Lite and DeepSeek-V2, training for approximately 1 trillion tokens (see extra details in Appendix B.1). What they did specifically: "GameNGen is trained in two phases: (1) an RL-agent learns to play the game and the coaching periods are recorded, and (2) a diffusion model is skilled to produce the following frame, conditioned on the sequence of previous frames and actions," Google writes. DeepSeek was able to practice the model utilizing a data heart of Nvidia H800 GPUs in just round two months - GPUs that Chinese companies had been not too long ago restricted by the U.S. An unoptimized model of DeepSeek V3 would wish a bank of high-end GPUs to answer questions at cheap speeds. The minimum deployment unit of the decoding stage consists of forty nodes with 320 GPUs.
- 이전글Too Busy? Try These Tips to Streamline Your India 25.02.01
- 다음글Deepseek: The Google Strategy 25.02.01
댓글목록
등록된 댓글이 없습니다.